Asynchronous Federated Unlearning
Ningxin Su, Baochun Li, University of Toronto,
IEEE International Conference on Computer Communications (INFOCOM) 2023
[Paper] [Slides] [Source Code]
Thanks to regulatory policies such as the General Data Protection Regulation (GDPR), it is essential to provide users with the right to erasure regarding their own private data, even if such data has been used to train a neural network model. Such a machine unlearning problem becomes even more challenging in the context of federated learning. where clients collaborate to train a global model with their private data. When a client requests that its data be erased, its effects have already gradually permeated through a large number of clients, as the server aggregates client updates over multiple communication rounds. Thus, erasing data samples from one client requires a large number of clients to engage in a retraining process.
In asynchronous FL, different clients progress at different speeds naturally in their local training. Intuitively, as Figure 1 shows, if we allow some clients to move forward towards global convergence while retraining only a small subset of the clients as data samples are erased, the inherent overhead of retraining can be substantially mitigated. A simple yet effective mechanism is to divide all clients into a small number of clusters, and aggregate client updates within the confines of each cluster only. The immediate effect of such clustered aggregation is that, if any client requests that its data samples be erased, only clients within the same cluster need to be retrained, while other unaffected clusters may continue with normal FL training.
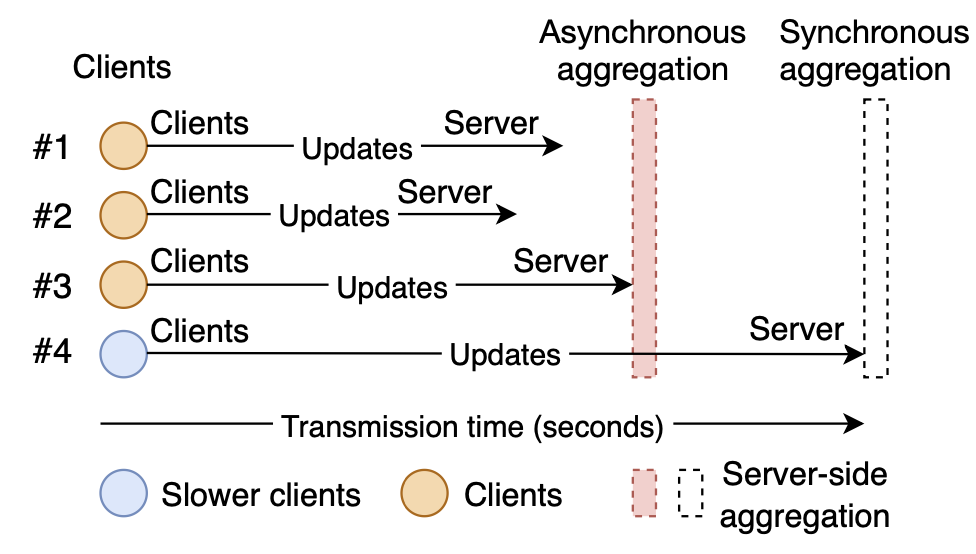
Figure 1: In asynchronous FL, clients spend different amounts of time for training and communication, and the server only needs to wait for a subset of clients to report back.
Machine Unlearning
With the recent emergence of regulatory policies that require corporations to provide the right to erase private data from users, machine unlearning has garnered increasing research attention. As illustrated in Figure 2, with the machine unlearning process, a new neural network model should be produced by unlearning all the effects of any private data that is requested to be erased. Existing research on machine unlearning aims to produce the unlearned model with the highest possible efficiency, without taking the naïve approach of retraining an initial model from scratch.
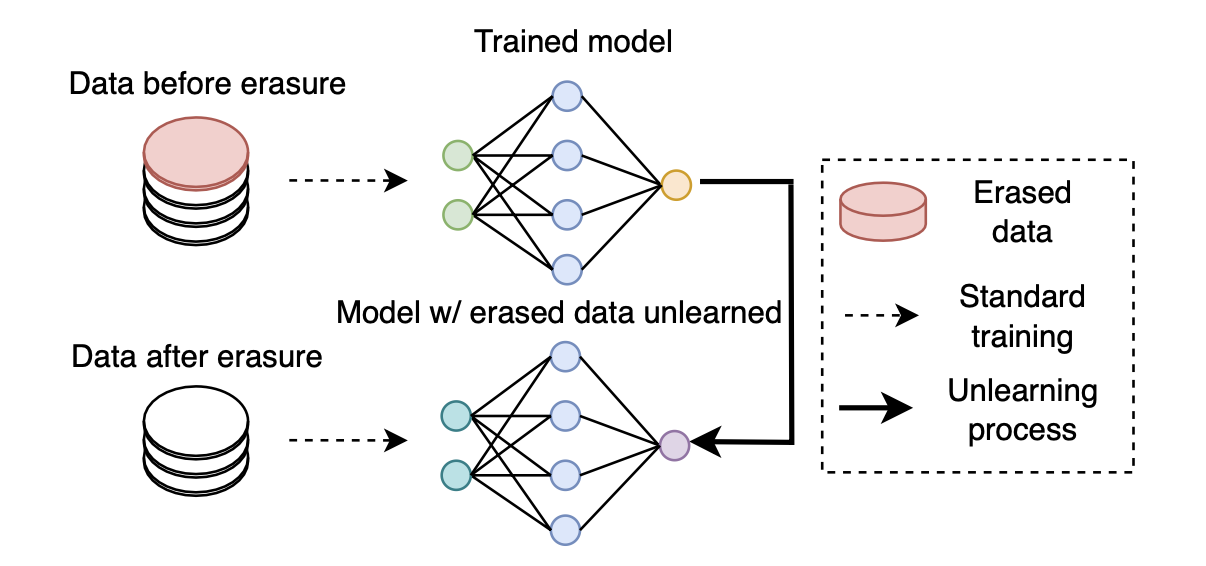
Figure 2: The primary goal of the machine unlearning process is to produce a new neural network model with the erased data unlearned, equivalent to a model initialized and then trained without using the erased data.
Knot — Our New Federated Unlearning Paradigm
We propose to construct a “firewall” between clusters of clients in the system, such that server aggregation is carried out within each cluster only. With such a mechanism, which we refer to as clustered aggregation, the ripple effect of one client’s contributions will only affect other clients in the same cluster, and clients outside the cluster will no longer need to be retrained. Figure 3 shows how clients can be clustered and how the server aggregates the updates within each cluster only. It is worth noting that our new mechanism of clustered aggregation is orthogonal to any innovations in the retraining mechanism: it is complementary to both the naïve mechanism of retraining from scratch and all its alternatives using approximation algorithms.
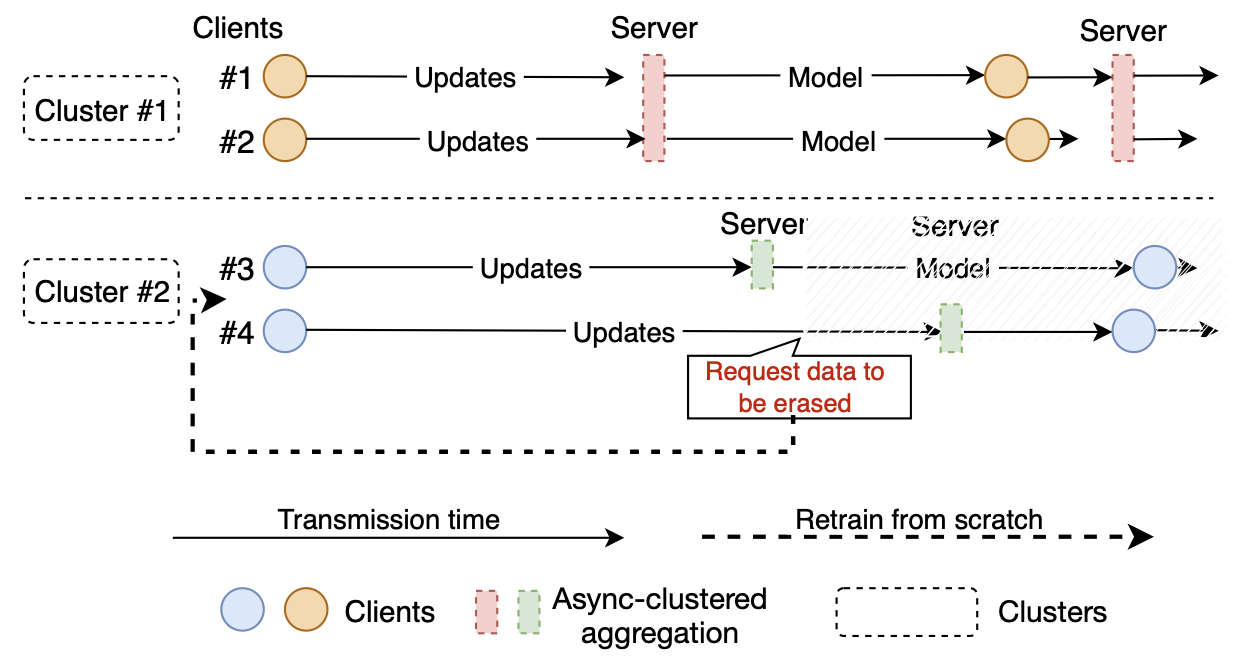
Figure 3: Example of asynchronous clustered aggregation where four clients have been assigned to two clusters. If client #4 requests to erase the effects of its data from the server, only clients in cluster #2 need to be retrained, while clients in cluster #1 may proceed normally with their FL training process.
While existing work on federated unlearning focused on improving its performance with more efficient retraining algorithms, we sought to take a decidedly different and orthogonal approach in this work with the introduction of clustered aggregation. The efficacy of our approach hinges on the intuition that the retraining process can be constrained to within a cluster only, if server aggregation is only performed within each cluster, and training sessions in the other clusters can be carried out asynchronously. We are the first to propose asynchronous federated unlearning, taking advantage of the well-recognized performance benefit of asynchronous FL. Knot, our optimization-based clustered aggregation mechanism, pushes the performance envelope further by not only formulating the client-cluster assignment problem as a lexicographical minimization problem, but also proving that it can be solved efficiently using a linear program solver. With our scalable and reproducible implementation, we have shown in Table 1 that the wall-clock training time with Knot is up to 85% better than FedEraser, a state-of-the-art approximation algorithm, even when retraining from scratch. Last but not least, our experiments were designed to be reproducible, and we have provided public access to our source code.
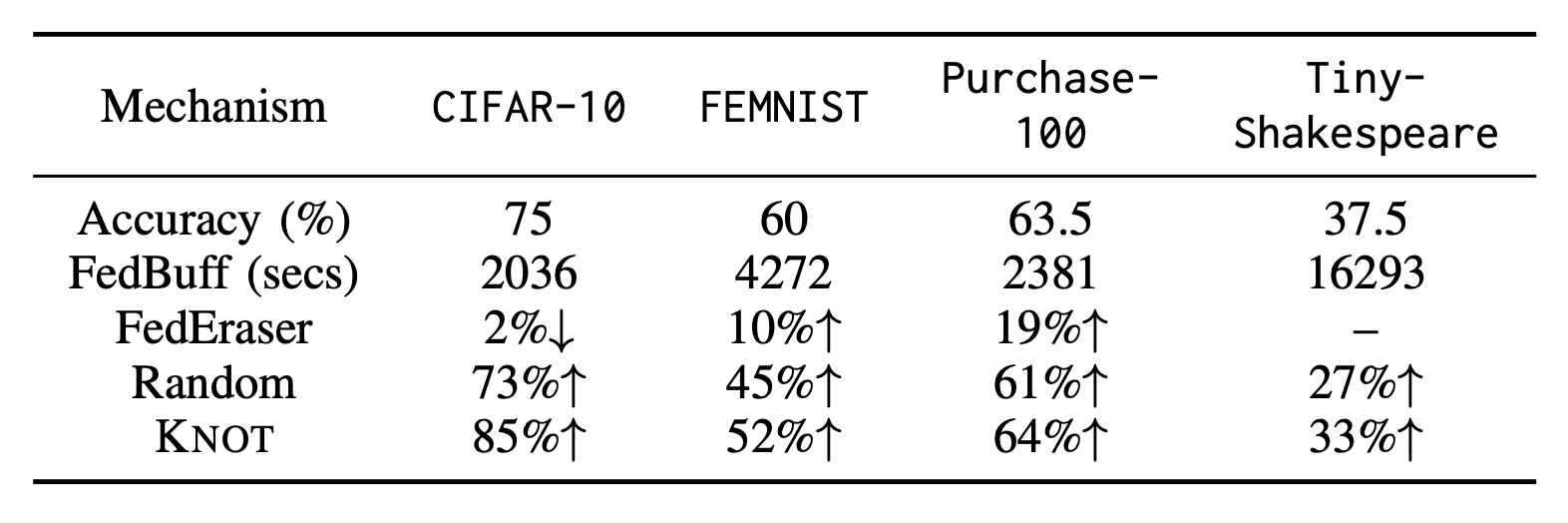
Table 1: Knot vs. its competitors: a comparison regarding the wall-clock times needed to converge to a target accuracy (or perplexity).
BibTeX
@inproceedings{knot_su2023,
author = {Ningxin Su and Baochun Li},
journal = {Proc.~Int'l Conference on Computer Communications (INFOCOM)},
publisher = {IEEE},
title = {Asynchronous Federated Unlearning},
year = {2023},
}